杜克大学研发新平台 让AI可从人类反馈而不是大数据集中学习
在第一堂驾驶课上,教练可能会坐到旁边,在每次车辆转弯、停下以及进行微调时,给出即时建议。倘若是父母,他们则可能会多次抓住方向盘并大喊“刹车”。随着时间流逝,此类纠正措施和意见会变成经验和直觉,让人们成为独立且具备能力的驾驶员。此外,虽然人工智能(AI)的发展让自动驾驶汽车成为了现实,但用于训练此类车辆的教学方法与副驾驶教练的方法仍有很大的差距。与提供具体建议和实时指导不同,AI主要通过庞大的数据集以及广泛的仿真实验进行学习,不管其应用场景如何。
杜克大学平台(图片来源:杜克大学)
据外媒报道,在此背景下,美国杜克大学(Duke University)和美国陆军研究实验室(Army Research Laboratory)的研究人员研发了一个平台,可帮助AI更像人类一样执行复杂任务。该AI框架的缩写为GUIDE。
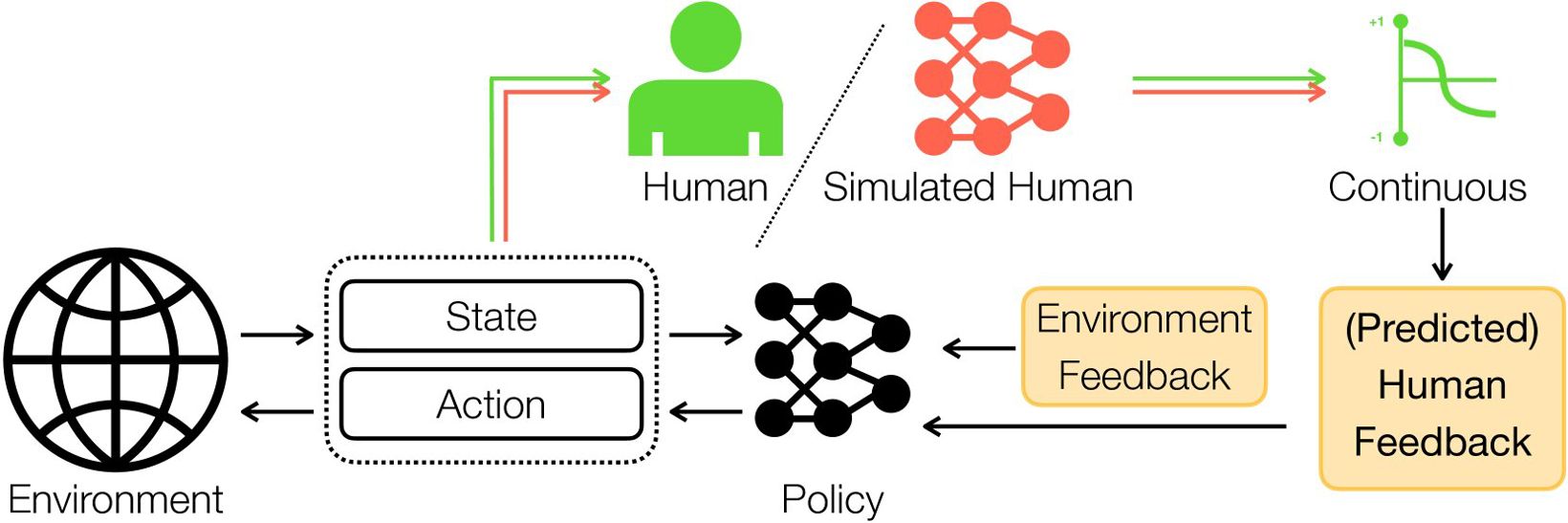
杜克大学机械工程与材料科学、电气与计算机工程、计算机科学系教授兼杜克大学通用机器人实验室负责人Boyuan Chen表示:“对AI而言,基于有限学习信息的快速决策任务依旧是一项挑战,现有的训练方式通常受限于对庞大的现有数据集的依赖,并且对传统反馈方法的适应性也有限。我们的目标是通过引入实时连续的人类反馈,来缩小这一差距。GUIDE的工作方式是让用户实时观察AI的动作,并提供持续的细微反馈,类似于一位经验丰富的驾驶教练不会只喊‘左边’或‘右边’,而是提供详尽的指导,以让学员能够逐步改进,深入理解。”
在首次研究中,GUIDE帮助AI学会掌握捉迷藏游戏的最佳策略。该游戏包括两位甲壳虫状的玩家,一个为红色,一个为绿色。尽管两个玩家都由计算机控制,但只有红色玩家致力于提升其AI控制器的能力。
游戏在中心设有C形围栏的方形场地中进行,大部分游戏场地仍旧是黑色的未知领域,直到红色的搜寻者踏入新的区域,揭示其隐藏的内容。
当红色AI玩家追逐另一方玩家时,一位人类训练师会对其搜索策略给出反馈。此前的这类训练策略只允许有三种人类输入信息——好,坏或中立,GUIDE则让人类训练师将鼠标指针悬停在滑动条上,以提供实时反馈。
该实验包含40名未曾接受过训练或不具备专业知识的成年参与者,是此类实验中规模最大的一次。研究人员发现,仅10分钟的人类反馈就能大幅提升AI的表现。与当下最先进的人类指导强化学习方法相比,GUIDE方法在成功率上提升了30%。
研究人员还证明,人类训练师仅需在短期内发挥作用。当参与者给予反馈时,该团队会依据特定场景、特定时间点的见解,打造一个仿真版人类训练师AI,从而让搜寻者AI能够在人类厌倦协助其学习时,继续接受训练。
GUIDE的另一个发展方向是探索人类训练师的个体差异。针对50名参与者开展的认知测试表明,空间推理能力以及快速决策能力等特定能力,会大大影响一个人能否高效指导AI。此类研究结果显示出一些可能性,如通过具有针对性的训练来强化上述能力,以及探索其他有助于成功指导AI的因素。
此类问题也表明,开发更具适应性的训练框架具有巨大的潜力。此类框架不但专注于教授AI,还能够提升人类能力,以构建未来的人类 AI团队。通过解决上述问题,研究人员希望构建一个未来,在其中,AI不仅能够更高效地学习,还能够更直观地学习,从而缩小人类直觉与机器学习之间的差距,让AI能够在信息有限的环境中更独立自主地运行。
该团队展望未来研究,计划通过整合语言、面部表情、手势等多种通信信号,为人工智能构建一个更为全面和直观的交互框架,让其能够从人类互动中学习。该研究也是该实验室致力于打造下一代智能系统的一部分,目标是与人类合作,共同解决AI和人类都无法单独解决的任务。
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
如有疑问请发送邮件至:goldenhorseconnect@gmail.com
- 杜克大学研发新平台 让AI可从人类反馈而不是大数据集中学习2024-12-09
- 唐唯实,没有“谢幕演出”2024-12-09
- 世界杯赛程表2021足球,世界杯 赛程2024-12-09
- 英超2019积分排名榜,2019年英超积分榜新浪2024-12-09
- 比利亚雷亚尔比分分析,比利亚雷亚尔比赛直播2024-12-09
- 维拉纽瓦球衣号码,维拉vs纽卡斯尔联2024-12-09
- 奥运会金牌数最多的运动员,奥运会金牌数最多的运动员排名2024-12-09
- nba黄蜂队英文,nba球队黄蜂队2024-12-09
- 德国14世界杯阵容,德国世界杯阵容20142024-12-09
- 2002年世界杯冠军成员,2002年世界杯冠军球队2024-12-09