基础设施软件2.0-中|盖世大学堂舱驾、行泊一体系列知识讲解
在自动驾驶和智能交通系统领域,关键议题包括多模态数据融合、局部重建、标注及模型训练优化。本文重点讨论了激光雷达点云畸变匹配技术,以提升高速场景下初始化成功率和回环检测精度。同时,介绍了利用学习方法进行规划检测,及通过离线模型和动态3D检测增强模型泛化能力。
一、局部重建的挑战与应对策略
在自动驾驶数据处理流程中,局部建图是关键环节,尤其是在单clip建图时,需确保性能。然而,在实际应用中,高速场景下的局部重建面临诸多挑战。一方面,高速行驶时系统初始化困难;另一方面,回环检测失败率较高。回环检测用于识别车辆是否回到同一地点,对多个clip间的聚合至关重要,通过检测结果可利用优化方法将不同clip聚合。
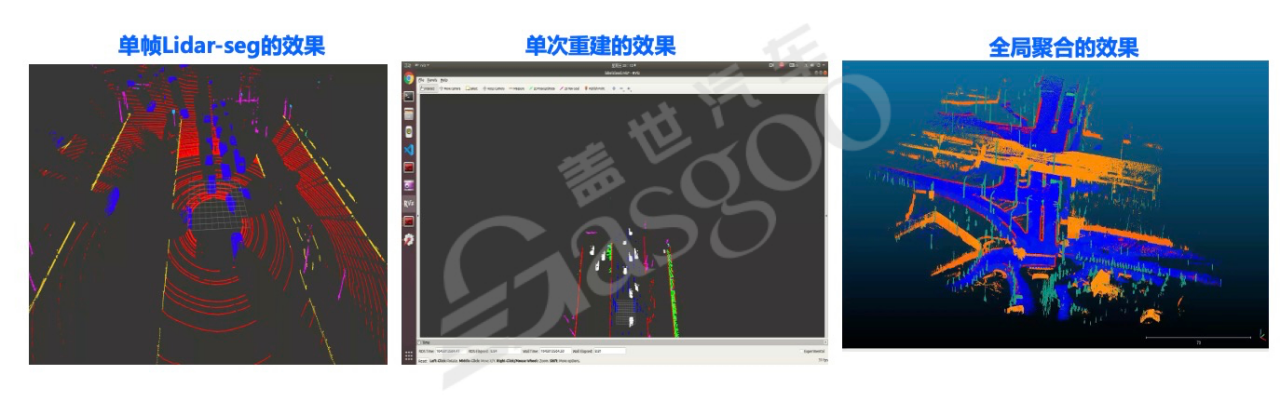
针对这些问题,目前采取了一系列有效解决方法。利用轮速计和GPS提供强先验信息,轮速计能精准提供速度信息,借助该信息对激光雷达点云进行去畸变和匹配,可使初始化成功率达到98%以上。回环检测则采用Learning based features方法,学习激光雷达关键点进行匹配,聚合成功率能提升至90%以上。此外,充分利用离线模型,如动态3D检测离线模型抠除动态点云,雷达set模型对激光雷达点云分类,增强关键类别权重,减少对次要散点的依赖,有效去除干扰。
二、数据聚合与标注优化策略(一)聚合策略与目的
数据聚合是提升标注效率和构建完整局部地图的重要手段。聚合的目的主要有两个:一是平摊标注成本,若将大量clip聚合成图,只需标注一次,便可为众多clip生成真值;二是构建更完整的局部地图,由于部分复杂场景(如大十字路口)单次采集难以观测全面,通过多趟采集聚合数据,可使局部环境重建更完整。

在实际操作中,采用了合理的聚合策略。以10000个clip为例,首先通过策略筛选出质量最高的10个clip进行聚合标注,其余clip虽进行聚合,但不更新地图,以此避免误差累积。同时,考虑到数据质量,夜晚、阴雨天等点云质量差的场景数据,虽可用于定位,但不适合建图和聚合。
(二)标注模型与流程优化
基于map TR进行改造,利用聚合后的BEV图作为输入,输出标注结果,简化了模型结构,提升了模型泛化性,为云端标注提供了基础。由于标注图分辨率要求高导致图幅较大,因此采用按轨迹切分(如切成九宫格)的方式,将切分后的图分别输入网络,再进行后处理和拼接。
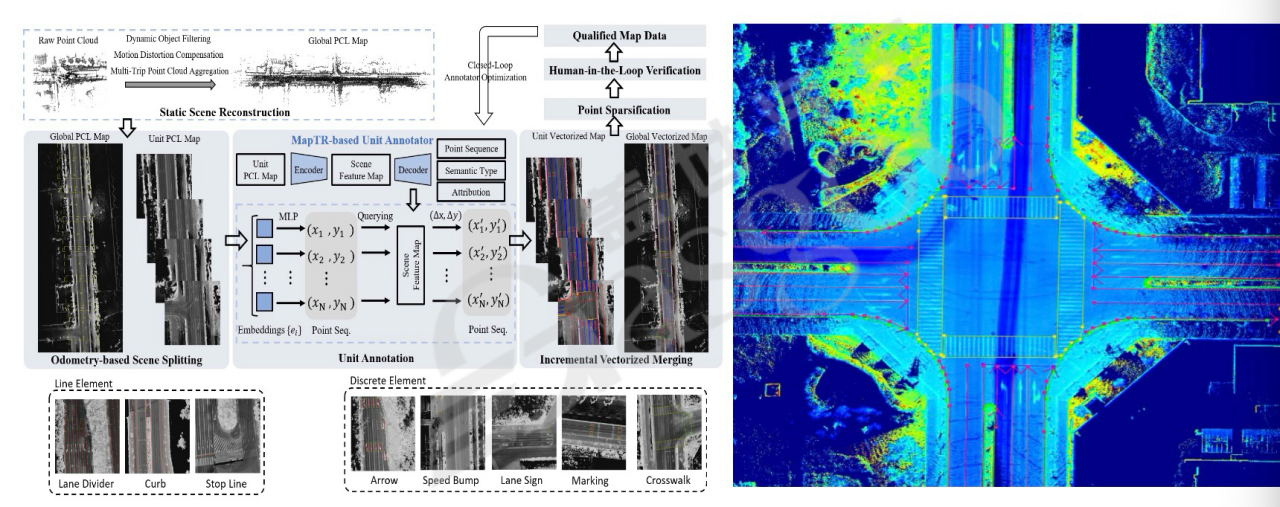
标注完成后,进行人工质检。质检时不仅查看标注图,还将标注结果投影到视频上,对比2D与3D标注结果的一致性。若发现不合格数据,将其作为训练数据更新离线模型,随着数据积累,模型性能会不断提升。此外,针对激光雷达在某些场景(如雨天、城区破旧道路)下难以识别车道线的问题,引入相机颜色信息,通过实时获取相机和雷达外参,优化算法进行点云与图像的对齐,利用纹理贴图辅助标注,符合人类驾驶感知原理。
三、不同场景下的标注应用与差异(一)定位复用与特殊场景标注
利用已有的标注结果进行定位复用,当车辆再次经过已标注区域且感知出现问题时,通过与地图匹配优化,可生成真值作为训练数据集,提高标注效率。在不同场景下,标注策略有所不同。例如,潮汐车道可通过2D模型在图像上的预刷结果投影到3D空间进行标注;在定位时,可利用关键点特征提升精度,同时要考虑真值定义和数据筛选问题。
雨雪天、夜晚等特殊场景下,由于激光雷达点云失效,难以直接标注。此时,利用晴天建图数据,通过定位方法为这些场景生成真值,避免了重建图模糊无法标注的问题。但在使用定位生成真值时,需注意真值与图像要素的对齐精度以及数据筛选,确保真值的可靠性。
(二)不同地图类型与泊车场景标注
4D-Label静态标注与图商高清地图存在差异。图商高清地图使用昂贵传感器和高精度定位设备,清晰度高、精度准,无需slam建图即可拼接成高精度地图,但可扩展性差,部署成本高,地图更新慢。4D-Label标注采用普通采集车和一般精度传感器,可实时标注和重定位,不存在地图更新限制,能满足感知需求且无需维护完整地图,定位精度横向可达10厘米,适用于多种场景。
泊车场景标注具有独特性,由于缺乏GPS信号,无法进行传统聚合。因此,通常进行完整采集并构造回环以保证定位精度。在泊车场地图重建中,需检测地库的关键要素(如斑马线、减速带、柱子、库位点等),对定位精度要求极高(误差小于5厘米),以避免泊车刮蹭。
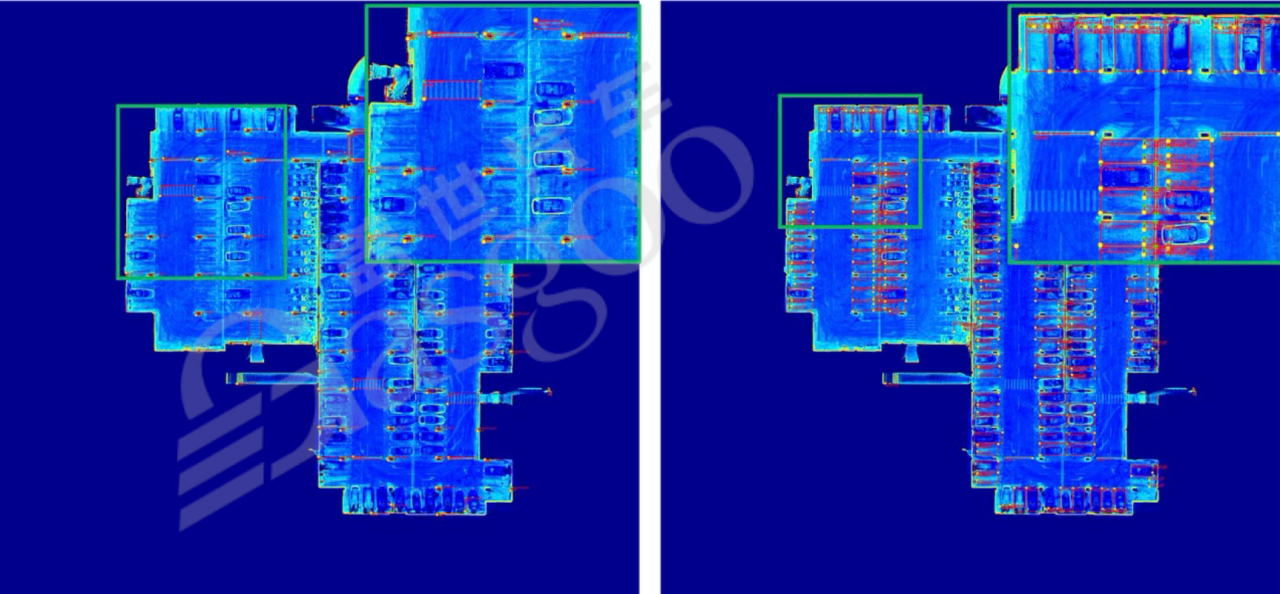
四、动态标注与特殊物体标注(一)动态标注方法与模型应用
动态标注主要针对3D检测、跟踪和预测网络。目前采用大模型预刷方式,利用前期积累的数据训练端到端模型,融合camera和激光雷达数据。在标注过程中,通过时间差值将3D检测物体投影到图像上,与图像进行交叉验证,只有当投影与图像物体重合度高时,才将其作为高质量真值,否则舍弃,以此确保标注数据的准确性。
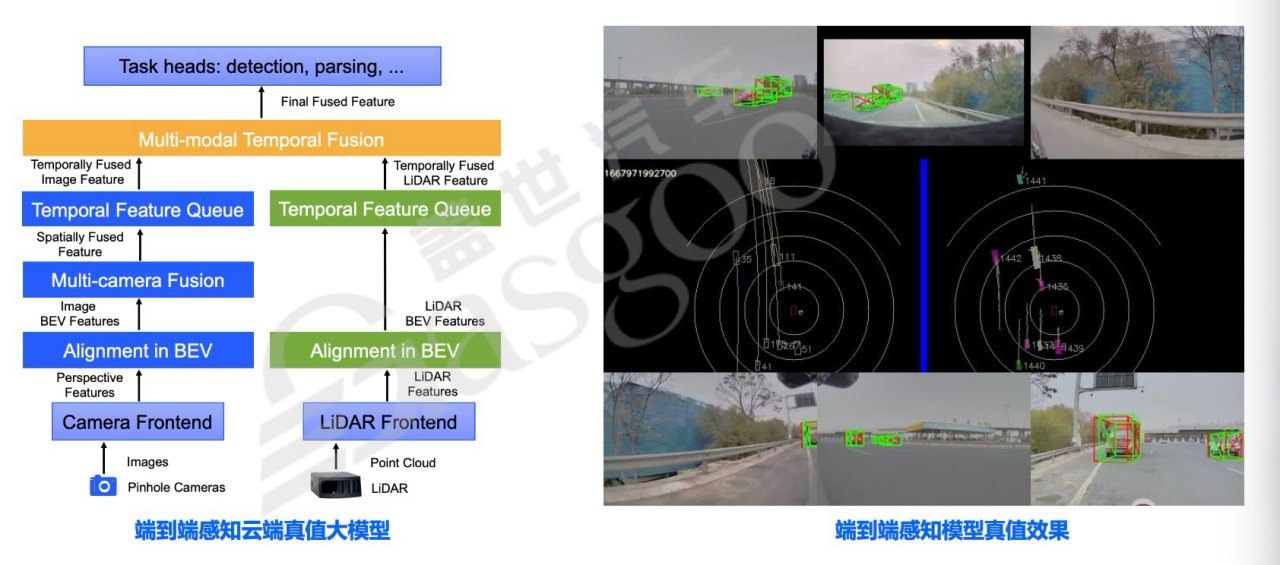
在模型融合方面,尝试了多种方式。前融合(数据层面融合)虽有一定优势,但存在上限不高、对偏差敏感的问题;特征级融合则在空间和时间上对激光雷达和相机特征进行融合,以获取更准确的感知结果。对于远距离标注(300米以外)难题,采用多车联合采集(组合车队采集)或V2X传递标注结果的方式,但多车联合采集效率较低。
(二)特殊物体标注策略
以锥桶标注为例,由于现有激光雷达模型中无锥桶类别,采用先做语义图提取3D bounding box伪标签,再与2D检测结果交叉验证的方式输出标注结果。这种方法充分利用了激光雷达语义分割中有类似障碍物类别的特点,有效解决了锥桶标注难题。

五、纯视觉标注方案探索(一)纯视觉标注的特点与挑战
纯视觉标注方案主要面向无激光雷达的量产车(如20万以下车型)数据标注,对数据闭环至关重要。与多模态方案相比,纯视觉方案避免了不同传感器间的外参标定和同步问题,标注真值与视觉模型的对齐度更好,但在动态物体重建方面面临挑战,因为通过视觉呈现动态物体在3D几何中是难题。
纯视觉标注流程与多模态类似,需进行4D空间重建。静态重建采用Structure From motion技术,先对单个clip进行三维重建获取pose和稀疏3D点,再进行MS重建得到语义点云后标注。然而,该方法计算成本高,使用CPU计算耗时久,使用GPU虽可加速但成本高昂。为降低成本,采用分而治之策略,单独重建路面和灯牌等要素。
(二)纯视觉标注的技术实现
1.路面标注技术:路面标注技术路线是采用76V或7V同步,结合轮速IMU和GNN信息进行刷分模式重建。由于纯视觉重建缺乏尺度信息,先利用轮速IMU和GNN融合得到带真实尺寸的轨迹,再通过相似性变换赋予刷分模式重建结果尺度。之后,利用稀疏点和其他约束进行路面数字化,采用Nerf方法重建路面。
在重建过程中,针对刷分模式重建效率低(复杂度为图像数量的4次方)的问题,利用初始化优化,减少图像匹配次数,采用单视角重建结合多视角三角化和全局BA优化,提升计算效率,使RTE达到0.5%,RE达到100米偏0.2,接近激光雷达精度。同时,采用基于学习的特征提升弱纹理区域重建的鲁棒性,重建成功率可达80% - 90%。

2.动态标注与Occupancy标注:动态标注比静态标注更具挑战性。目前主要有两种方法,一是用2D检测结果结合规则后处理生成3D bounding box;二是利用大模型提供初始值,结合轨迹优化和后处理生成真值。云端模型精度比端上模型高,通过云端模型指导端上模型,提高标注效果。
Occupancy标注采用离线模型学习深度网络,利用多相机时空约束训练网络,并引入仿真数据提升边缘效果。训练时,DRO将BA优化嵌入网络,通过预测深度更新depth和pose,增强泛化性能。该方案在50米内有较好测距精度(小于8%),结合光流可得到3D空间中Occupancy和Occupancy flow的真值,但与激光雷达相比仍存在抖动问题。
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
如有疑问请发送邮件至:goldenhorseconnect@gmail.com
- 基础设施软件2.0-中|盖世大学堂舱驾、行泊一体系列知识讲解2025-02-14
- 基础设施软件2.0-下|盖世大学堂舱驾、行泊一体系列知识讲解2025-02-14
- 黑芝麻智能武当C1200完成DeepSeek部署2025-02-14
- 特朗普关税大棒之下,美国车企是加价还是转移产能?2025-02-14
- C Talk | Mobileye:自带AI基因,引领未来出行变革2025-02-14
- 保隆科技|从双目到三目,走在视觉系统技术前沿2025-02-14
- 基础设施软件2.0-上|盖世大学堂舱驾、行泊一体系列知识讲解2025-02-14
- 保时捷将在德国裁员1900人2025-02-14
- 【国际快讯】特朗普签署行政令推行对等关税;日产汽车启动全球重组计划;保时捷计划到2029年前在德国再裁减1,900名员工2025-02-14
- EasyPark集团收购泊知港以优化驾车体验2025-02-14