世界模型,智能驾驶质变的良药?
在比亚迪、奇瑞等车企争相于推进高阶智驾功能的普惠化时,聚焦于智驾技术前沿的科技巨头们,已经开始向新的方向攻进——世界模型。
2023年,特斯拉在CVPR上向公众介绍了一款新的端到端模型,它由完整的4D神经网络构成,能够理解世界运行的规律;在2025 CES上,英伟达宣布将推出世界模型Cosmos,其专为理解物理世界打造,可预测和生成“物理感知”的视频。

图片来源:英伟达官网
而在国内,2024年7月27日,NIO IN 2024蔚来创新科技日上,蔚来正式发布中国首个智能驾驶世界模型 NWM,即可以全量理解信息、生成新的场景、预测未来可能发生的多元自回归生成模型。
理想则紧随其后,在NVIDIA GTC 2025上发布了MindVLA,这款基于自研的重建 生成的云端统一世界模型,能够深度融合重建模型的三维场景还原能力与生成模型的新视角补全及未见视角预测能力,构建接近真实世界的仿真环境。
特斯拉、英伟达布局,理想、蔚来快速跟进,显而易见的是,世界模型已经成为智能驾驶领域绕不开的新技术趋势,甚至在“AI教母”李飞飞World Labs、谷歌DeepMind入局后,世界模型的意义已经被看做是整个AI领域的关键节点。
由此便产生了一系列疑问,以智驾为技术落地形式的车企与科技巨头,为何集体选择了世界模型?这一全新技术架构究竟是灵丹妙药,还是又一个技术噱头?它究竟能为当下智能驾驶带来何种提升?
为什么我们需要世界模型
世界模型诞生的初衷,实际是为解决AI领域的痛点的。
以智能驾驶为例,2024年特斯拉曾对外发表一段声明称,启用特斯拉Autopilot的车辆每行驶763万英里发生一起车祸,而未使用Autopilot的驾驶员则每行驶95.5万英里就会发生一起车祸。作为佐证,美国国家公路交通安全管理局和联邦公路局的数据显示,在美国平均情况下每行驶67万英里就会发生一起车祸。这表明特斯拉的智能驾驶技术确实降低了事故发生率。
然而,尽管特斯拉发布了一系列有关智能驾驶的安全报告,仍未能完全消除公众对其安全性的疑虑。例如在2016年,一辆特斯拉Model S就曾在Autopilot状态下与白色半挂卡车相撞,导致驾驶员不幸身亡。此外,2022年林志颖也在驾驶一辆特斯拉Model X时发生了碰撞事故,虽然事故原因仍无明确的官方定论,但坊间仍有部分人认为,此次碰撞与可能发生在Autopilot状态下。
对智能驾驶安全性的质疑不仅来自于消费者,自2022年至今,因担心特斯拉智能驾驶技术可能导致撞车事故,美国管理机构已下令多次召回——这无疑会对智驾技术的发展带来严重影响,因为智驾技术与企业赖以生存的数据与盈利皆来自于规模化量产,而消费者与监管机构的不信任必然会削减来自下游主机厂的订单。
市场对智能驾驶的不信任体现在不安全,而不安全在技术层面则体现在感知算法的空间理解能力——事实上,智能驾驶自2020年至今,所发布的多项技术架构均与提升空间理解能力有关。
例如2021年,特斯拉正式提出了BEV Transformer的技术范式,其中BEV算法能够将特斯拉环绕车身的8个摄像头提供的视觉特征拼接为时序序列,并做到跨摄像头的空间关联,接下来再将通过Transformer生成的每个位置的语义和几何信息映射到一个鸟瞰图空间中,进而智驾提供一张计算机视角下的环境地图。
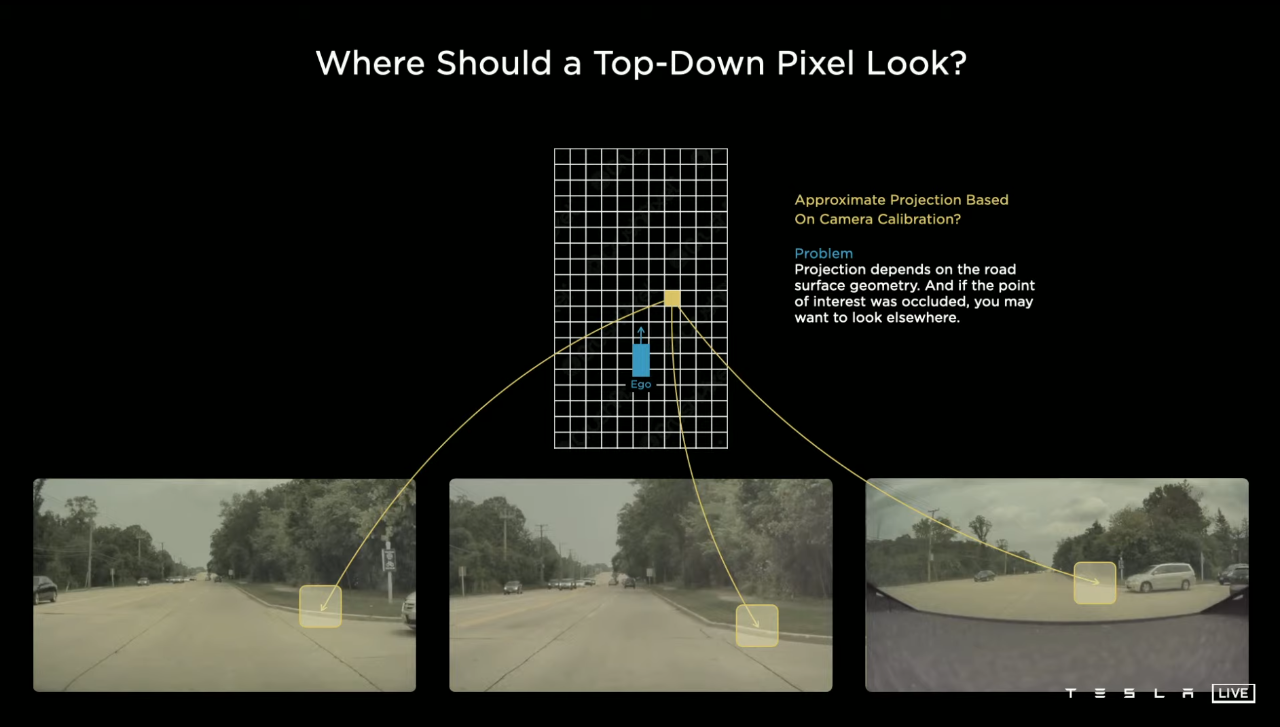
图片来源:TESLA AI DAY直播
这一技术范式一经发布,立刻被全球智驾企业引用,成为了当下智驾技术的通用范式,但随着该范式的普及,其不足也开始暴露,就是BEV算法的框架是基于二维的,这导致其不仅缺乏对周围环境中各类障碍物的高度信息,也无法准确感知并映射复杂的异形障碍物。此外,感知系统如果没能成功进行特征识别,也将导致智驾无法正确做出相应的规控策略。
于是在2022年,特斯拉发布了Occupancy Network,这一技术架构下特斯拉会将感知环境划分为1cm³的体素网格,进而把世界转化成一个稠密的3D占据场。如此一来,感知系统无需再预设地面平坦或物体形状,就能识别异形障碍物,并且还支持移动障碍物轨迹跟踪,这使得智驾无需依赖高精地图中的精度信息,也能实现复杂的道路拓扑推理。
Occupancy Network把对环境的感知升级为三维化描述,但其感知缺失表面材质信息,对细小物体等不确定性的描述不足,于是在此之后,感知算法在空间理解能力的再次升级方向变为了重构世界,端到端架构又被特斯拉推上前台。对比之前规则 模块化算法的结构,端到端可以用单一模块实现从传感器信息输入到车辆控制,从而减少信息损失,让系统能够应对更多场景,具备更强的泛化能力,这能让输出的规控策略更加拟人化,并大幅降低长尾极端场景Corner case出现的可能性。
但是问题又出现了,如果仅依赖端到端模型,时间维度信息的融合和推演都是定长的逻辑,自动建模长时序信息的能力相对匮乏。在智驾系统中,预测未来事件,并评估其影响的能力对安全性和效率也至关重要能想象变化才是真正的时间理解,想象的真实度和丰富度是理解深度的体现。
由此,世界模型出现在了行业视野内,成为了接下来提升智驾能力的必经之路。
世界模型能为智驾带来什么
世界模型的灵感源于人类自然形成的世界心智模型。我们通过感官获取的抽象信息在大脑中被转化为对周围世界的具象理解;这些“模型”早在人类开始研究AI之前就已存在。基于这些模型,我们的大脑对世界进行预测,从而影响我们的感知和行动。
举个例子,智能驾驶在输出规控策略之前,会基于周围一定障碍物的移动轨迹来预测其接下来的路线,进而计算车辆自己的可行驶空间,而人类驾驶时则会优先通过观察障碍物的种类、外形特征来评估接下来的行驶轨迹——同样是汽车,一辆轩逸和一辆GT-R必然存在不同的驾驶风格,但该经验是人类基于潜意识完成的,对于智驾来说则需要有意识的推演。所以基于这一点,人类驾驶员可以本能地调整自己的驾驶策略,而智驾不能,正是这种世界心智模型的潜意识推理能力,让行业内诸多学者认为,世界模型就是AI实现人类级别智能的前提。
简单来说,世界模型就是让智能驾驶模拟人类与世界交互,去经历更多的事情,进而更准确地认识、预测这个世界,而不是将范围拘泥于“驾驶”这一件事中。而在被运用到智驾领域后,世界模型将通过生成式大模型生成带有预测性质的视频数据,实现Corner Case的多样化训练;并采用强化学习的方法认识复杂驾驶环境,从视频输出驾驶决策。目前构建世界模型的方法主要有两种:一种是凭空想象,“无中生有”;另一种是根据现有信息完善信息,如输入文本、图片、视频等生成更多更丰富的视频。
首先以英伟达的Cosmos为例,这个世界模型平台上有一系列开源、开放权重的视频世界模型,其作用也非常明确,就是为机器人、智能驾驶等在物理世界中运行的AI系统生成大量照片级真实、基于物理的合成数据,以解决该领域数据严重不足的问题。据英伟达介绍,Cosmos 经过了9000万亿个token的训练,数据来自2000万小时的真实世界人类互动、环境、工业、机器人和驾驶数据,并且模型可以针对特定应用进行微调。
图片来源:英伟达官网
对此,黄仁勋曾表示,“机器人技术的ChatGPT时刻即将到来。世界基础模型对于推动机器人和自动驾驶汽车开发至关重要,但并非所有开发者都具备训练自己的世界模型的专业知识和资源。我们创建Cosmos是为了让物理AI普及化,让每个开发者都能用上通用机器人技术。”
而蔚来的世界模型NWM则是能够基于真实世界的视频进行重构和推演,在重新编辑的过程中,分解出背景中静态的、动态的信息,这可以让NWM切换到任意角度分析对应的细节信息,不仅可以由此建立起一个有无限可能的仿真世界,还可以构建出一个全凭想象、但完全基于真实世界物理法则的世界。
据蔚来官方表示,NWM可以在0.1秒内推演出216种可能发生的轨迹,寻找最佳决策,然后在接下来的0.1秒内,根据外界的信息的输入,重复更新内在时空的模型,那再去预测216种可能性。以此循环,跟随驾驶轨迹持续预测,得到驾驶的最优解。“这就是在万千“平行世界”中寻找最优解,像是在漫威电影中,拥有了时间宝石的奇异博士,可以操控时间旅行,从所有结果中寻找到能获取最终胜利的一个方案。”

图片来源:蔚来官网
除了提升智驾的安全性,世界模型通过理想MindVLA为智驾赋予了更多功能,例如其具备更强的通识能力,可以基于视觉感知识别出如星巴克、麦当劳等商店招牌,并在没有明确导航信息的情况下,自主漫游并寻找目的地;另外在收到用户类似“找个停车位”这样的模糊指令时,MindVLA可以借助世界模型强大的空间推理能力自主寻找车位并执行停车操作。
而在功能性提升的基础上,世界模型还能降低智驾企业的训练成本。在基于语言模型的智驾模型中,其输入是周围驾驶场景的图像数据,输出的则是诸如道路拓扑、各类交通参与者在内的语义信息,这导致其不具备自回归特性,需要投入大量人力标注数据,进而维持有监督学习;但在基于世界模型的自动驾驶大模型中,同样输入的是周围驾驶场景的图像,输出的却是下一个时序的场景图像数据,这类自回归模型的训练过程是无需数据标注的无监督学习。
不过,尽管世界模型展示出了诸多强大的能力,但其发展目前仍然面临不少挑战。例如在技术层面,现有世界模型对物理规律的建模仍停留在刚体运动层面,难以准确刻画流体、柔性体等复杂动力学行为,例如特斯拉在暴雨场景测试中发现,车辆对积水路面轮胎滑移率的预测误差达42%,导致制动距离偏差超过1.2米。此外,世界模型对时空连续性的建模精度直接影响预测可靠性,根据百度Apollo测试显示,8秒预测时域的轨迹误差呈指数增长,最大偏差达2.3米。
在数据层面,世界模型的训练与推理对算力提出严苛要求,例如特斯拉Dojo超算训练单模型需消耗28MW电力,这相当于相当于3万户家庭日用电量,成本达380万美元。另外参考wayve的世界模型,需要在64张A100训练15天,有65亿参数。视频解码模块也需要在32张A100训练15天,26亿参数量。从wayve展示的视频中可以看出很多若隐若现,或者中途车辆不断变化的情况,这也说明目前的世界模型生成的未来数据效果还比较一般。
总结
世界模型为智能驾驶带来了从“感知执行”到“认知决策”的范式跃迁。传统系统依赖规则库与特征识别,难以应对中国复杂的“人车混行”“道路突变”场景。而世界模型通过神经辐射场(NeRF)构建动态三维物理空间,在BEV视角下融合多模态数据,使车辆不仅能识别障碍物,更能理解其运动规律。这种物理规律的内化,让系统突破了依赖海量标注数据的局限,真正实现“举一反三”的类人推理能力,这些突破标志着智能驾驶从“辅助工具”向“认知伙伴”的进化。
作为深耕AI领域的观察者,我认为世界模型的价值不仅在于技术指标提升,更在于重构了人机协作的本质。当车辆能理解轮胎与路面的摩擦方程、预判道路参与者的特殊行为,智能驾驶将超越“拟人化”阶段,进化为具有环境认知与创造力的交通主体。尽管面临算力、数据等挑战,但谁能率先构建“物理规律 驾驶常识”的认知引擎,谁就能在这场出行革命中占据制高点。这不仅是技术的竞赛,更是对人类智能本质的深度探索。
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
如有疑问请发送邮件至:goldenhorseconnect@gmail.com
- 一天一个西红柿几天就能白 西红柿一天一个什么好处2024-04-26
- 流脑是什么病表现和症状有哪些 流脑疫苗打自费还是免费的?2024-04-26
- 体检发现尿酸高怎么办 需要服药吗为什么?2024-04-26
- 脊柱侧弯是怎么形成的原因是啥 脊柱侧弯正骨能矫正过来吗?2024-04-26
- 脓毒血症是什么病 脓毒血症是怎么引起的一般多久治好?2024-04-26
- 生物胺类物质包括什么 生物胺对人体的影响有哪些2024-04-26
- 手脚血管堵塞最佳治疗方法 感觉手脚血管有点堵塞怎么回事2024-04-26
- 夜尿多就是肾有问题么 夜尿多是肾虚还是前列腺炎?2024-04-26
- 脓毒血症症状表现有哪些 脓毒血症最怕三个征兆2024-04-26
- 淫秽物品认定标准是什么 传播淫秽物品牟利罪如何判定?2024-04-26