从第二阶段到第三阶段:灵活性的极致追求,软件的自主升级-下|盖世大学堂汽车大模型应用系列知识讲解
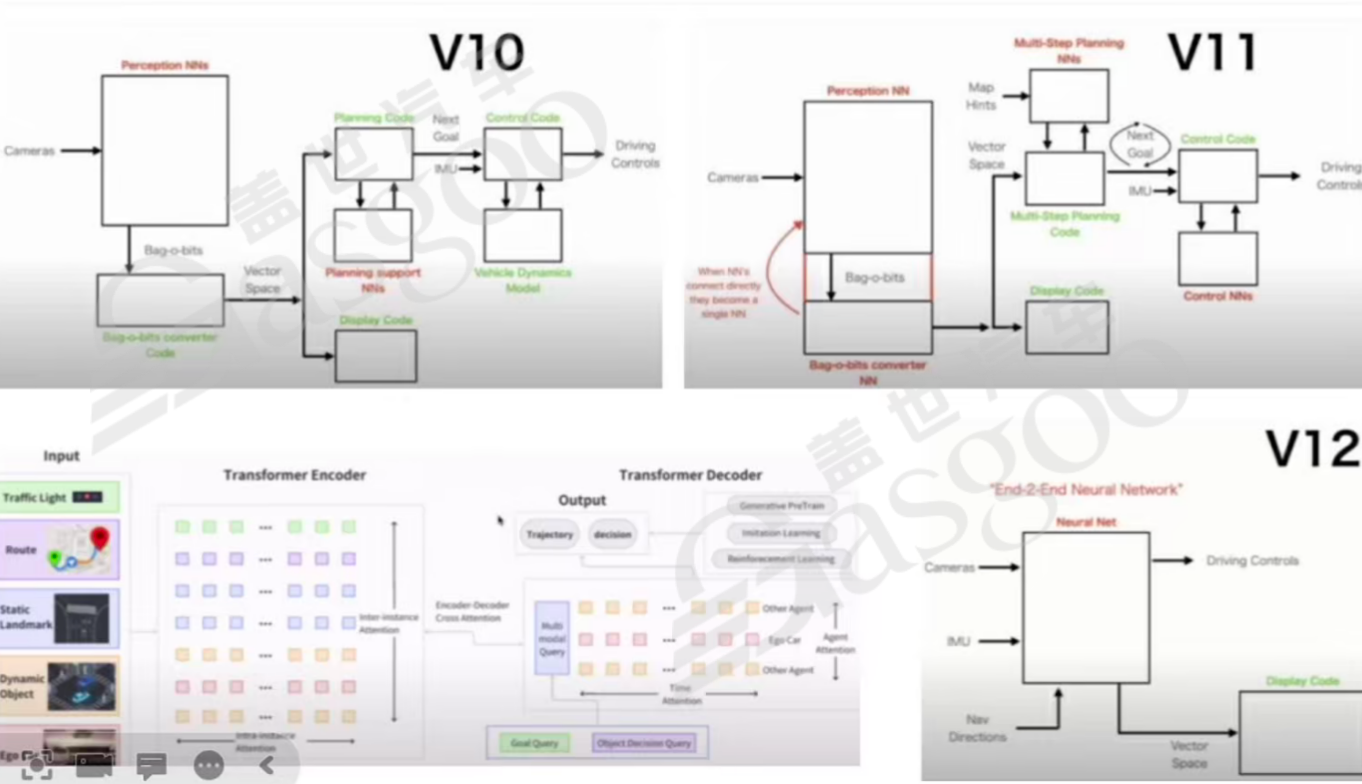
在技术飞速发展的当下,软件领域正经历着深刻变革,从第二阶段迈向第三阶段的过程中,对灵活性的追求达到了新高度,软件自主升级成为关键趋势。以特斯拉软件版本迭代为例,从V10到V12的演进,其软件架构图发生了显著变化。下图中绿色部分代表规则算法,红色部分代表感知算法,随着版本更新,红色部分占比逐渐增多,绿色部分重要性不断降低。到V12时,整个模型执行过程基本以网络模型为主,仅保留少量显示代码。这一变化反映出特斯拉在软件迭代中,不断强化神经网络模型的应用,逐步减少对传统规则算法的依赖,以提升软件的智能化水平。
在深入探讨软件发展趋势时,大模型是无法绕过的关键领域。大模型可以模拟人脑功能,在高维认知空间下转换不同模态的数据,实现与人类更广泛的直接交互。它能够完成多模态数据之间的转化,如将视频、文字、声音等转化为控制指令、文字、视频、矢量结果等。相比传统模型,大模型的参数规模通常在10亿以上,其核心优势在于能够理解环境的一般规律,如人类问答逻辑、物理世界规则等。虽然大模型的概念在一定程度上被滥用,但它在不同领域发挥着重要作用,且与传统模型有着本质区别。
从参数量来看,一般常用图像模型参数量在1000万-5000万,车端的端到端模型一般在1-3亿,而真正的大模型则达到百亿千亿级别,如ChatGPT。不同类型的大模型在处理任务上也有所不同。例如,将视觉定位、矢量信息、雷达原感知信息作为输入,以语言、执行指令等矢量作为输出,构成端到端模型;视频和矢量进出的属于World Model范畴;语言进、视频或声音出的类似Sora;ChatGPT则以语言进、语言出为主,如今也逐渐向多模态拓展。这些模型虽应用于不同业务领域,但都采用Transformer结构,这与过去模型结构多样、数据固定的情况截然不同。
在大模型出现之前,模型研发多是尝试不同结构,以适配固定数据和任务,如同不断更换人员来适应固定工作环境。而大模型时代,Transformer成为通用结构,通过不同任务驱动模型提升认知,类似改变教育方式培养人才。大模型在与人类交互方面也与传统模型有很大差异。传统模型通常作为规则算法系统的附属品,无法直接参与人类社会活动,如酒店人脸识别模型,需与其他系统配合才能发挥作用。而大模型如ChatGPT,可在广泛领域与人类直接对话,实现无人类或规则算法环节介入的平等交流。
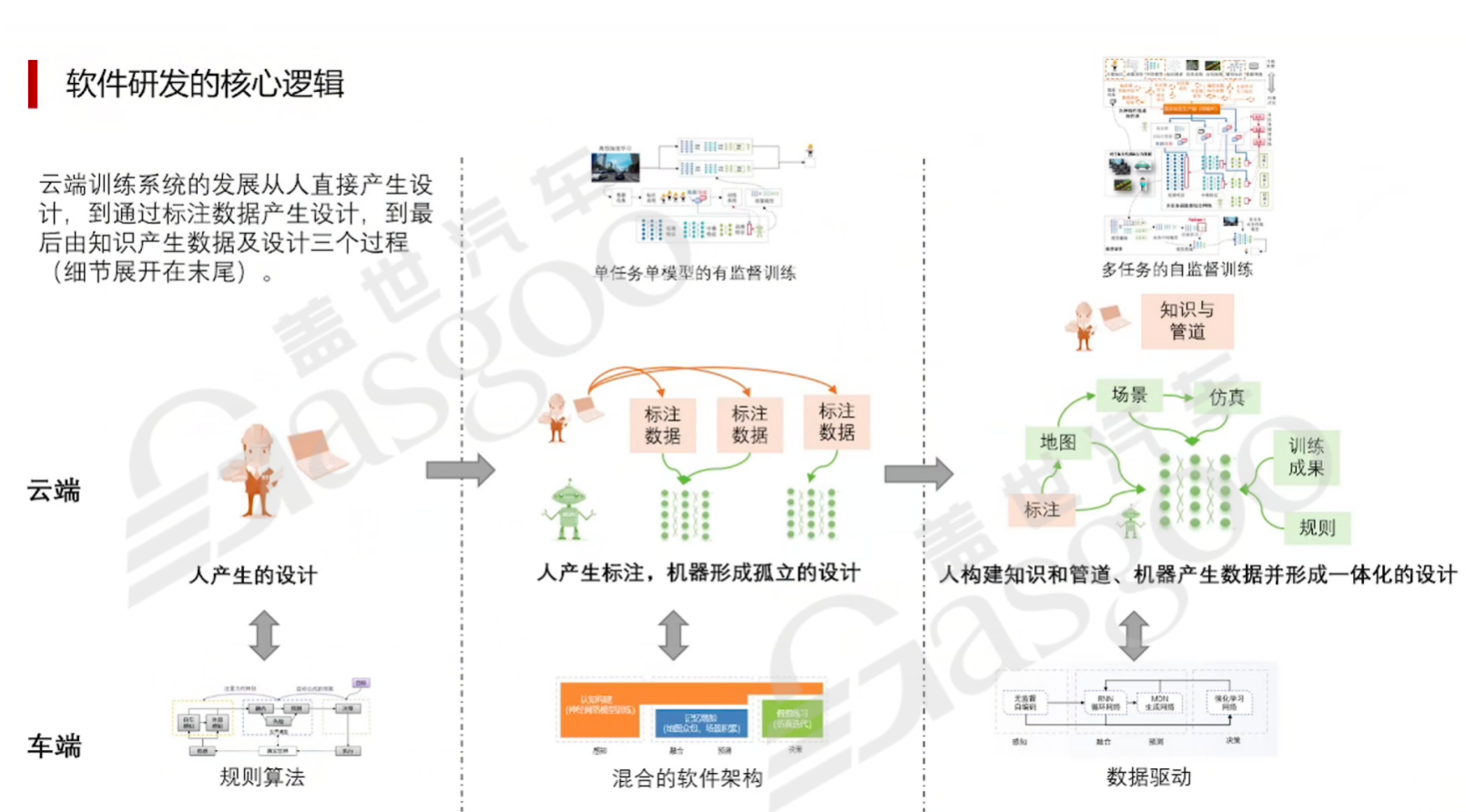
大模型具有多方面的重要作用。在强化认知方面,它能以通用模型支持多种任务,如语言沟通、决策判断、行为计划分解和逻辑梳理等,背后是对知识背后一般逻辑和组织逻辑的把握。虽然在语言类通用规则上已取得一定成果,但视觉、视频和智能驾驶等领域的大模型,行业内尚未形成统一观点,其整合也处于探索阶段。在构成生产力方面,大模型与以往工业革命成果有着本质区别。过去的工业革命成果虽影响人员流转,但本身难以直接构成生产力,人类始终是生产的核心驱动力。而大模型直接构成生产力,在产业升级时,可能导致劳动力需求减少。例如,通用机器人概念的出现,使机器人能在业务需求变化时无需改变产品形态即可适应生产过程,这使得人类作为生产衔接环节的价值面临挑战。若大模型与机器人形成闭环,其影响范围将进一步扩大,对就业结构和社会经济产生深远影响。
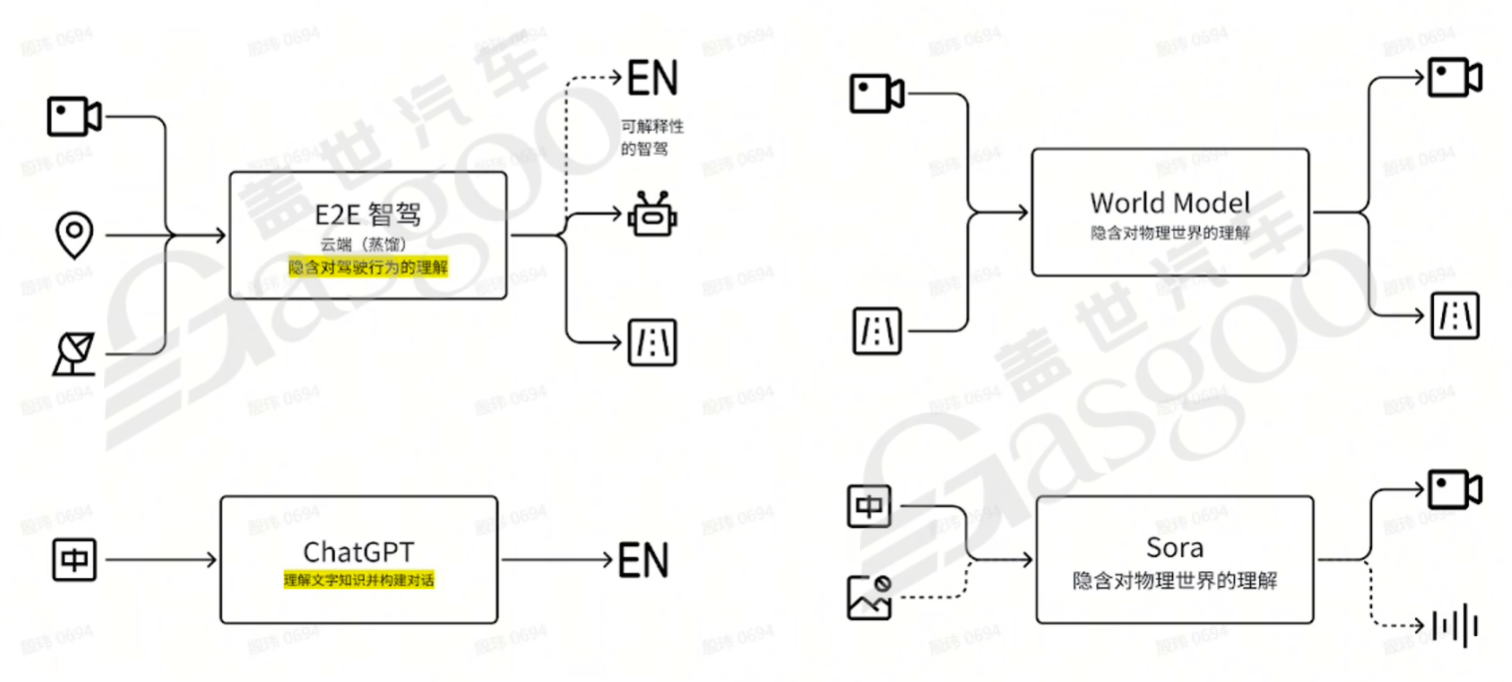
智能驾驶和语言大模型原本属于不同行业,并无交集。但随着技术发展,它们在技术架构和逻辑上逐渐趋同,均朝着通用人工智能(AGI)的方向发展。特斯拉涉足机器人和汽车领域,正是基于这两种业务在技术层面呈现出的强耦合性。智能驾驶从可控性出发,向可扩展性发展,经历从规则逻辑向模型逻辑的迭代;语言模型则以泛用性为基础,如今越来越关注可控性和价值判断问题。在发展过程中,两者均采用强化学习的策略,如RLHF,以Transformer为核心架构,遵循数据驱动的逻辑。
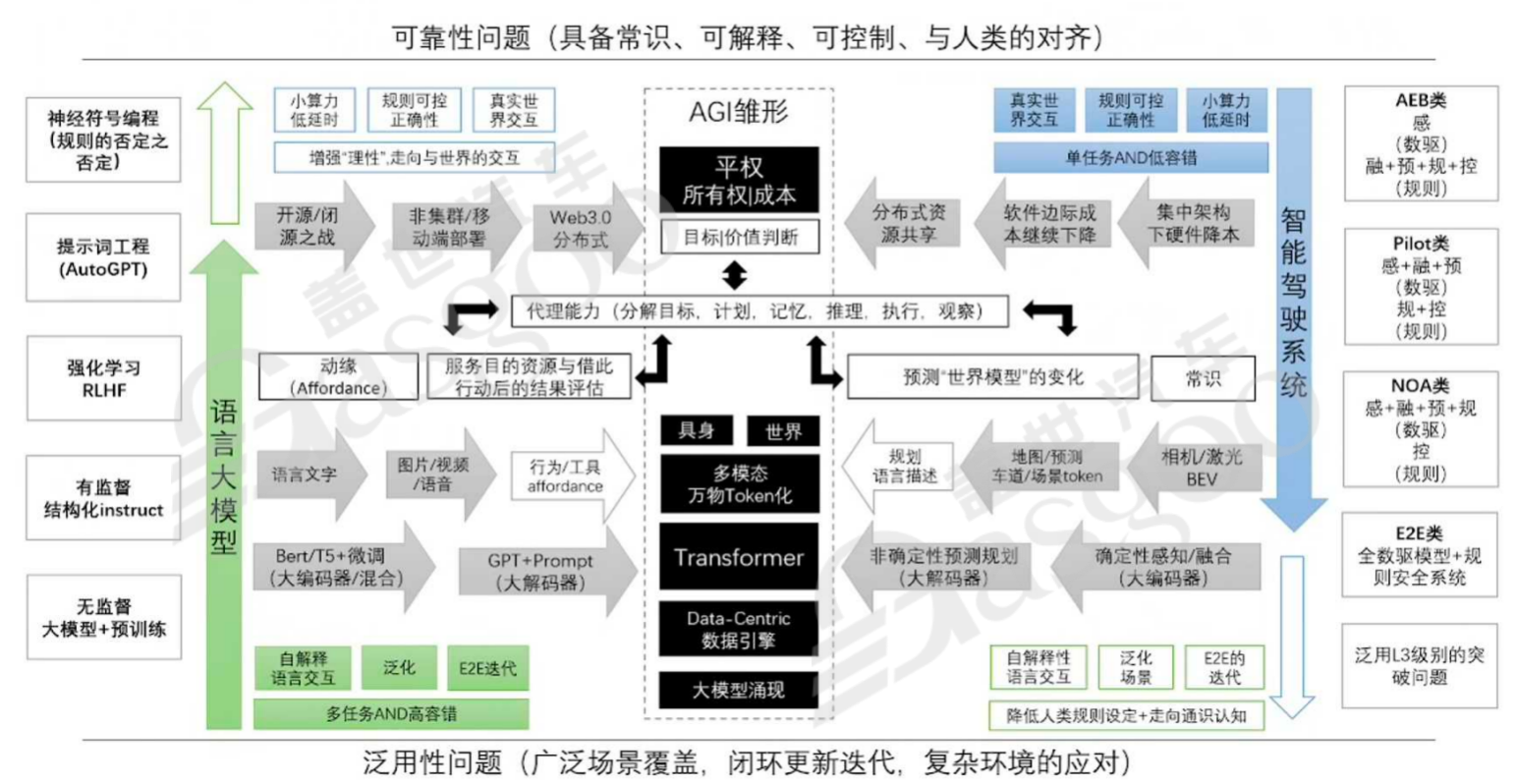
大模型具有一些独特的关键特点。涌现现象是其中之一,当模型规模达到某个阈值时,模型对某些问题的处理性能会呈现快速增长,这被称为涌现能力。这种现象类似于物理上的相变,即量变引发质变。例如,在自然语言处理任务中,一些大模型在规模达到一定程度后,在算术运算、单词重组、语言翻译、问答等任务上的表现有显著提升。目前,学界和业界都在深入研究涌现现象产生的原因,主流观点是通过数学和物理学方法解释其内在机理,如从信息熵、自由能最小原则等角度进行探索。这不仅对模型设计人员确定技术路线至关重要,也涉及到智慧产生的本源问题。
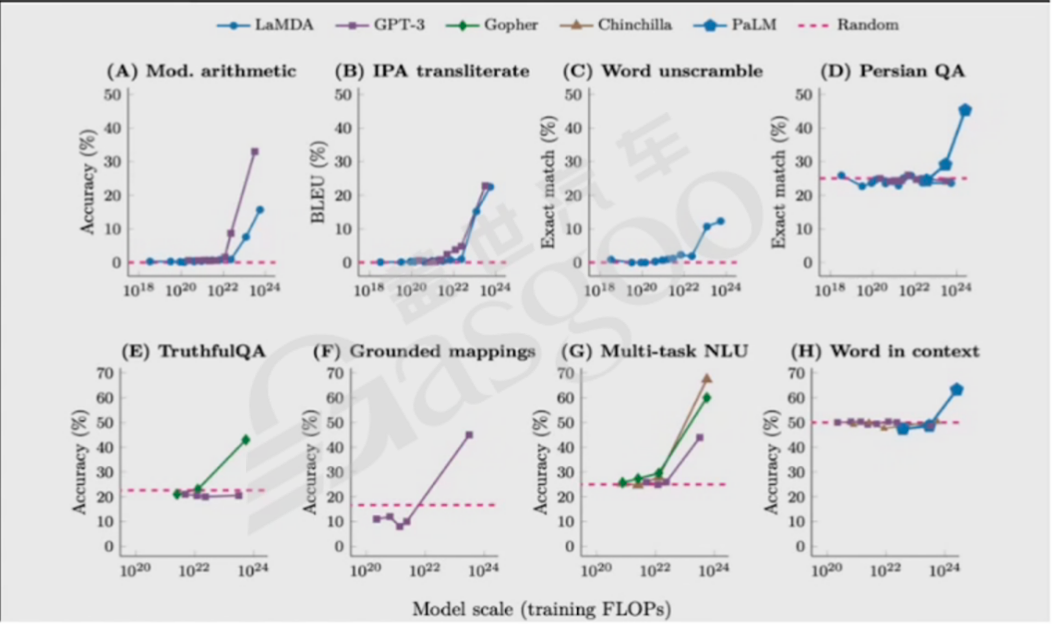
从技术发展历程来看,大模型的涌现现象带来了技术范式的转变。过去模型多采用微调方式,效果较为恒定。而大模型通过提示词的方式实现了技术突破,尽管在发展初期不被看好,但随着模型规模和能力的提升,这种方式逐渐成为主流,推动了大模型技术的快速发展。
大模型目前主要作为基础设施被使用。在“小模型”阶段,算力需求相对较低,个体和小企业尚可负担,使用1张GPU卡即可开展相关工作。但进入超大规模预训练模型阶段,大模型的超大参数和海量数据对算力提出了极高要求,普通玩家难以企及。例如,GPT的算力需求为18kpetaFLOPs,GPT-3达到310 Mpeta FLOPs,PaLM更是高达2.5 Bpeta FLOPs。从成本角度看,GPT-3的训练使用了上万块英伟达v100GPU,总成本高达2760万美元,个人若要训练出一个PaLM,花费在900至1700万美元之间。这使得大模型的研发和训练成为少数具备强大资源的机构或企业的专属领域,大多数使用者只能依赖现有的大模型作为基础,接入到各种应用系统中,而无法独立创建大模型。
在大模型的发展过程中,Data-centric(以数据为中心)的理念逐渐兴起。与传统以模型迭代为主(Model-centric)的AI开发方式不同,大模型的成功很大程度上依赖于大量高质量的数据以及对数据引擎的重视。以GPT系列模型为例,从GPT-1到GPT-4,模型结构基本保持Transformer解码器不变,主要是通过扩大模型规模和数据规模来提升性能,这是典型的Data-centric过程。
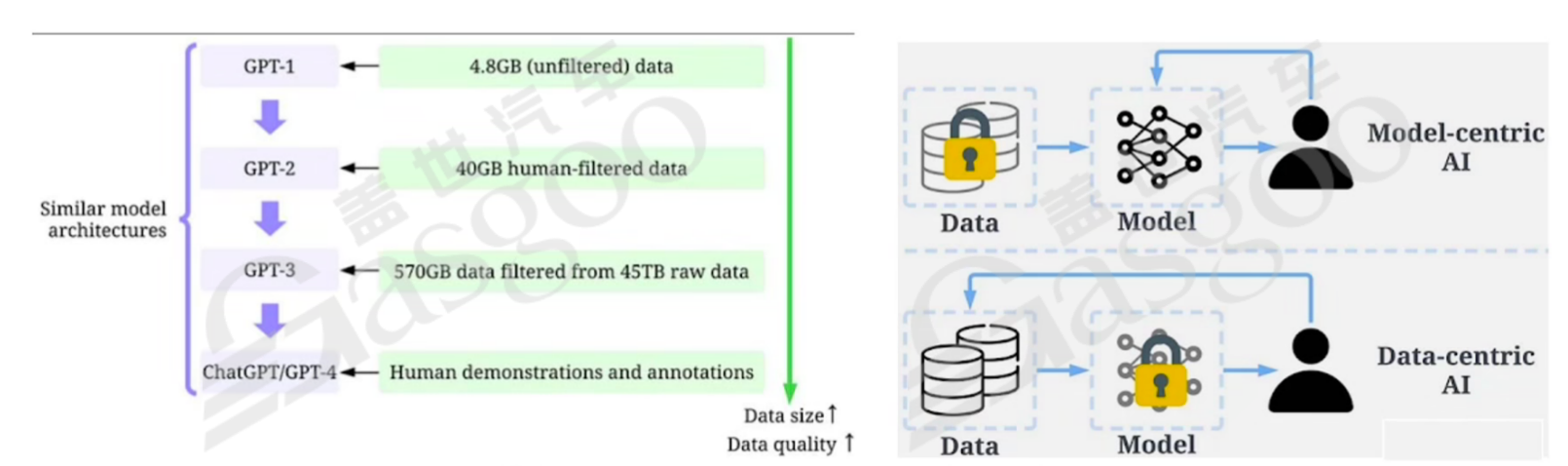
Data-centric与Data-driven(数据驱动)有着本质区别。Data-driven仅强调使用数据指导功能系统搭建,而Data-centric关注的是通过数据迭代而非模型迭代来改善系统性能。在实际应用中,Model-centric方式未充分考虑数据可能出现的问题,如标签不准确、数据重复和异常数据等,高准确率的模型可能只是对数据的“过度拟合”。而Data-centric方式将重点放在数据本身,认为数据在很大程度上决定了模型能力的上限,在实际场景中具有更大的潜力。
Data-centric AI主要包括三个目标:训练数据开发,即构建足够数量的高质量数据以支持机器学习模型的训练;推理数据开发,构建用于评估和解锁模型能力的数据,如通过对抗攻击评估模型鲁棒性,利用提示词工程产生新业务价值;数据维护,由于大模型需要不断更新,需采取措施持续维护数据在动态环境中的质量和可靠性,包括数据收集、标注、理解、质量保证、存储检索以及数据增强等工作。

在Data-centric的大模型应用中,数据运维管理至关重要。与过去对数据管理相对粗放的方式不同,如今在模型应用过程中,需要对数据进行持续运维。不仅要关注训练数据,还要重视推理数据的开发,提示词工程就是推理数据开发的重要组成部分。通过设计合适的提示词,可挖掘大模型的潜在价值,如利用提示词让模型进行文本解释、数学计算、情感分析等任务。提示词工程的出现,使得数据和模型的界限变得模糊,模型可被视为一种数据或数据的“容器”。通过提示词,能够利用大语言模型合成所需数据,这些合成数据又可用于训练模型,在GPT-4上已验证了这种方法的可行性,展现出大模型自我进化的可能性。
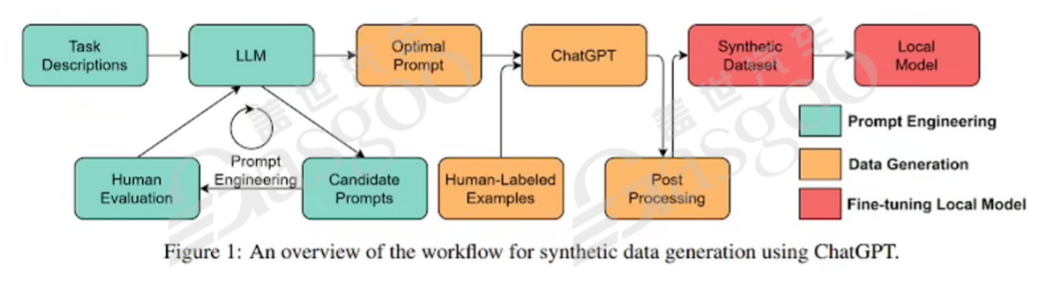
随着大模型技术的不断发展,在实际应用中出现了一些新的概念和尝试。例如,有观点提出“艺人公司”模式,即除人员外,公司其他部分均由AI构成。尽管目前在实践中面临一些问题,但从长远来看,当智能机器人具备实际工作能力时,如何管理智能体之间的组织关系将成为关键问题。比如,如何确保审核模型准确履行职责,开发模型高效完成任务等。目前,已经出现利用语言模型进行自动化化学实验、代码编写等应用场景,通过语言模型的多维组织,实现数据产生和业务训练的相互推动,以一种类似“套娃”的方式发挥作用。在这一过程中,人类更多地扮演领导者或指导者的角色,负责梳理流程和进行必要的修正,而模型和机器则在实际运作中不断自我优化和完善。
综上所述,从软件架构的迭代到智能驾驶与语言大模型的融合发展,再到Data-centric理念的兴起和大模型的应用探索,技术的发展正深刻改变着软件领域的格局。大模型作为核心技术,在提升认知、构成生产力等方面展现出巨大潜力,同时也带来了诸如劳动力结构变化、数据管理挑战等新问题。在未来,随着技术的持续进步,智能体的组织管理、模型的可解释性和可控性等将成为研究和实践的重点方向,推动软件领域朝着更加智能化、高效化的方向发展。
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
如有疑问请发送邮件至:goldenhorseconnect@gmail.com
- 从第二阶段到第三阶段:灵活性的极致追求,软件的自主升级-下|盖世大学堂汽车大模型应用系列知识讲解2025-02-18
- 本田或将调整墨西哥和加拿大生产策略以应对特朗普关税威胁2025-02-18
- 从第二阶段到第三阶段:灵活性的极致追求,软件的自主升级-上|盖世大学堂汽车大模型应用系列知识讲解2025-02-18
- 红旗天工08区域上市发布会北京站落幕2025-02-18
- 卢放:岚图全品类车型将搭载华为乾崑智驾2025-02-18
- 理想汽车2025年第7周销量为0.75万辆2025-02-18
- 印尼1月汽车销量同比下降11.3%2025-02-18
- 华为与广汽合作首款车型或明年上市2025-02-18
- 特斯拉焕新Model Y在上海超级工厂正式量产2025-02-18
- 安道拓中国技术中心升级扩建完成,持续加码本土创新2025-02-18